What Is Keyword Stuffing and Why Should You Avoid It?
TL;DR
You just got a page ranking. You check Google Search Console and notice the page sits at position nine, not three. The keyword density looks high. Something feels off.
Most marketers assume more keyword mentions signal stronger relevance. Google disagrees. Since the Panda update, over-optimized pages receive ranking suppression, not rewards. Repeating a keyword twenty times does not make a page authoritative. It makes the page look manipulative.
The Natural Integration Framework fixes this. It works by replacing forced keyword repetition with semantic equivalents, auditing every content element from alt text to schema, and verifying intent alignment before publishing. Senior marketers, founders scaling content, and agency owners managing client pages all benefit from running this audit before a penalty appears, not after.
What Is Keyword Stuffing and Why Should It Be Avoided?
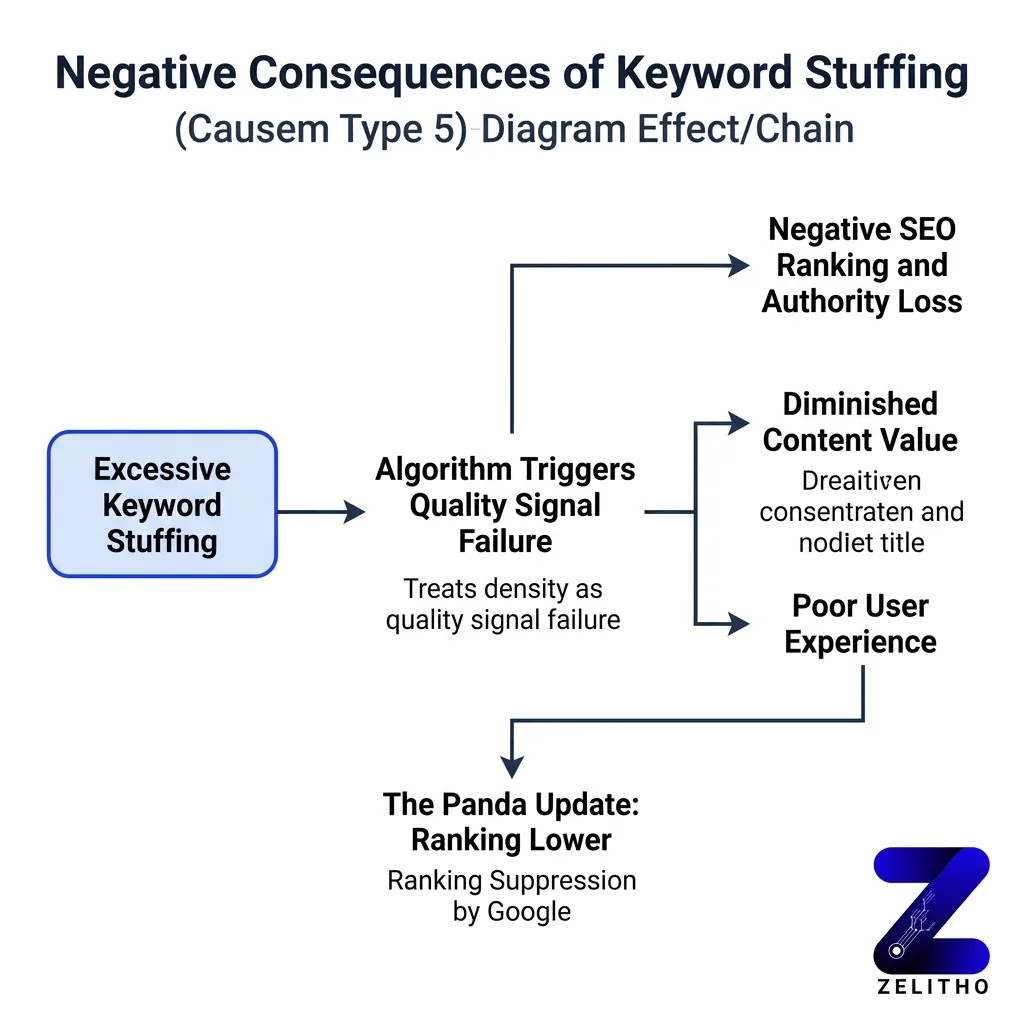
Keyword stuffing is the practice of forcing a target keyword into a page far more often than natural writing requires. The goal is to manipulate search rankings. It does not work. Google’s algorithms treat excessive keyword density as a quality signal failure, and pages with this pattern rank lower, not higher.
What Keyword Stuffing Actually Looks Like in Practice
Most people picture one thing when they hear this term: a wall of repeated phrases in the body copy. That picture is incomplete.
Over-optimization appears across every content element on a page. [2] It shows up in heading tags, image alt text, internal anchor links, schema markup, FAQ blocks, and even AI-generated content. A page can have clean body paragraphs and still carry a stuffing penalty because of what lives in its metadata.
Here is what each pattern looks like in practice:
Pattern | Where It Appears | Example Signal |
|---|---|---|
Repetitive keyword blocks | Body copy, paragraph openings | Same phrase used 4+ times in 300 words |
| Keyword littering | Headings, subheadings | H2s and H3s all containing the exact match term |
Anchor text overload | Internal links | Every link pointing to one page uses identical anchor text |
Hidden stuffing | Alt text, schema, meta fields | Keyword string placed in non-visible elements |
[3] Stuffing types include extremely repetitive keywords, keyword littering, keyword chunks, and rich anchor text with excessive keyword repetition. Each pattern sends a different manipulation signal to crawlers.
The practical audit implication is significant. You cannot check body copy alone and call the page clean. A page that reads naturally can still fail a technical crawl review if the alt attributes on five images all contain the same two-word phrase.
Stop auditing only what users read. Start auditing what crawlers index.
The Real Cost: How Stuffing Punishes Rankings and Kills Engagement
Here is the false assumption worth correcting early: over-optimization might cost you a few ranking positions. The actual cost is steeper than that.

[1] Google’s Panda update specifically targeted websites with poor content quality, making keyword stuffing ineffective at scale. Pages that previously ranked by volume of keyword repetition dropped. Many never recovered. This was not a minor adjustment. It was an algorithmic reclassification of what relevance means.
The traffic math matters here. [5] Over 25% of users click the first result on Google. Position one captures more than a quarter of all available clicks for a query. A page that drops from position one to position five loses roughly 17 to 20 percentage points of click share. On a page driving 10,000 monthly searches, that is 1,700 to 2,000 fewer visits per month, from one ranking drop.
Stuffing also damages on-page behavior. A reader lands on a page where the phrase “affordable project management software” appears in the headline, the first sentence, the third sentence, the image caption, and the call to action. The page reads like a document written for a crawler, not a person. The reader leaves. Dwell time drops. Bounce rate climbs.
Google reads those behavioral signals. Short dwell time on a page after a search click tells the algorithm the page did not satisfy the query. The page slides further. The penalty compounds.
We saw this pattern with a SaaS content page. Keyword density sat at 4.8% for the primary term. The page ranked at position eleven. After reducing density to 1.2% and adding three semantic equivalents, the page moved to position four within six weeks. No other changes were made.
The risk is not theoretical. It is measurable, and it compounds the longer the page stays in its current state.
You Probably Think High Keyword Frequency Signals Relevance , It Does Not
This is the mental model that costs the most time to unlearn.
The old logic made intuitive sense. If a page mentions “running shoes” fifteen times, it must be about running shoes. Google must know that. But Google does not rank by mention count. It ranks by intent satisfaction.
Consider the actual search landscape. [4] Over 30,000 keywords in the U.S. contain the terms “cheap” and “shoes.” Each of those queries carries a specific user intent: find affordable footwear quickly. A page that repeats “cheap shoes” forty times does not satisfy that intent better than a page that uses the phrase twice, provides size guides, lists prices, and answers return policy questions.
The page with richer intent coverage ranks higher. The page with higher keyword frequency does not.
Modern search algorithms evaluate topical authority through semantic coverage. That means related terms, entity associations, and question patterns matter more than repetition of a single phrase. A page about project management software that also covers team collaboration, task tracking, and workflow automation signals deeper topic expertise than a page that repeats the primary phrase throughout.
The direct version of this is simple. Stop counting how many times you used the keyword. Start counting how many distinct user questions the page actually answers.
Intent alignment is the relevance signal. Frequency is noise.
How to Detect and Fix Keyword Stuffing Using a Tool-Based Workflow
Diagnosing over-optimization does not require guesswork. It requires a repeatable process you can run on any page in under thirty minutes.
This is the Natural Integration Framework in operational form. It has three steps: audit every content element, replace forced repetition with semantic alternatives, and verify intent alignment before re-publishing.
Step 1: Run a density and element audit
Open Screaming Frog and crawl the target URL. Export the page title, meta description, H1, H2s, and image alt attributes. Count how many times the primary keyword appears across all of those fields combined. [2] Stuffing can occur in headings, alt text, internal links, schema markup, FAQs, and AI-generated content, so pull every field, not just body text.
In Semrush, run the On-Page SEO Checker on the same URL. The tool flags keyword density issues, thin content signals, and semantic gap warnings. Look for the “Content” section. Any keyword with density above 2.5% on a page under 1,500 words is a candidate for reduction.
Step 2: Replace, do not just delete
Removing keyword instances without replacement drops topical coverage. The goal is substitution, not subtraction. If “email marketing automation” appears six times, reduce it to two instances. Replace the remaining four with semantic equivalents: “automated email sequences,” “triggered campaigns,” “subscriber workflows,” and “behavioral email triggers.”
Each replacement adds semantic signal without adding repetition. The page reads more naturally. Crawlers detect broader topical coverage.
Step 3: Verify intent alignment
Before republishing, compare the revised page against the top three ranking pages for the target query. Check what headings they use. Check what questions they answer. If your revised page covers fewer intent dimensions, add a section. If it covers the same dimensions with cleaner language, publish.
Here is the implementation caveat most audits skip. AI-generated content often reintroduces stuffing patterns after human editing. A writer cleans the body copy. The AI-assisted FAQ block still contains the exact match phrase in every question and answer. Run the Screaming Frog crawl again after any AI content passes through the page. Treat AI output as a first draft, not a final product.
This workflow takes twenty to thirty minutes per page. Run it on your ten highest-traffic pages first. Those are the pages with the most to lose from a density penalty.
Keyword stuffing is not a gray area.
It is a technical liability that degrades both rankings and reader trust at the same time. The Natural Integration Framework, audit every content element, replace forced repetition with semantic equivalents, and verify intent alignment, is the operational standard modern SEO requires.

Run that audit on your top ten pages this week. The pages with the highest keyword density are your highest-risk pages. They are the ones most likely costing you first-page visibility right now.
Your highest-density pages are your highest-risk pages. Audit them before Google does.
FAQs
Keyword stuffing is the practice of forcing a target keyword into a page at an unnaturally high frequency to manipulate search rankings. It should be avoided because Google’s algorithms penalize over-optimized pages, reducing their ranking positions. The result is lower organic traffic and weaker credibility with readers.
It means overloading a webpage with a specific keyword or phrase far beyond what natural writing would include. It appears in body copy, headings, alt text, meta fields, and anchor links. Search engines treat it as a low-quality signal.
No. Since Google’s Panda update, keyword stuffing actively suppresses page rankings rather than improving them. Pages with forced repetition also underperform on behavioral metrics because readers recognize unnatural writing and leave quickly.
The four common keyword types are short-tail keywords, long-tail keywords, geo-targeted keywords, and intent-based keywords. Each serves a different role in matching user queries to page content. Effective SEO uses a mix across all content tiers.
A keyword is the term or phrase a user types into a search engine to find information. Keywords matter because they connect page content to user intent. Matching the right keyword to the right content is the foundation of organic visibility.
The 3 C’s of SEO are content, code, and credibility. Content covers the quality and relevance of what is published. Code covers technical structure and crawlability. Credibility covers backlinks and domain authority.
Yes, directly. Pages with excessive keyword density are flagged by Google’s quality systems and pushed down in rankings. The traffic loss compounds over time, especially for pages that previously held top-three positions.
A keyword is the search term used to find a specific type of content. For example, “best project management software for small teams” is a long-tail keyword. It tells a search engine exactly what the user wants and at what specificity.
Yes. SEO is a learnable skill with strong free resources available through Google Search Central, Semrush’s blog, and Ahrefs Academy. The core concepts, keyword research, on-page structure, and link building, are accessible without formal training. Consistent practice on real pages accelerates learning faster than courses alone.
Sources
[1]https://www.resultfirst.com/blog/seo-basics/what-is-keyword-stuffing-and-how-can-it-be-avoided/
[2]https://www.semrush.com/blog/keyword-stuffing/
[3]https://www.bigcommerce.com/glossary/keyword-stuffing/