What Is Keyword Density? A Simple SEO Definition and How It Is Measured
TL;DR
You ran your content through a tool, got a keyword density score, and now you’re not sure whether 1.8% is good, risky, or irrelevant. That specific number caused a pause. That pause is worth examining.
Most people respond by adding or removing keyword mentions to hit a target percentage. That approach treats a diagnostic metric as a performance goal, which is the wrong use entirely.
The Repetition Audit Framework gives content teams a repeatable process: define the term, calculate once using occurrences divided by total words multiplied by 100, then check whether any section crosses 2% in a way that disrupts reading flow. This framework applies directly to senior marketers auditing existing pages, founders building scalable content systems, and agency owners reviewing client drafts before publication. The goal is catching excess, not chasing a number.
What Is Keyword Density in SEO?
Keyword density measures how often a target term appears in a piece of content relative to the total word count. You calculate it by dividing keyword occurrences by total words, then multiplying by 100. It does not measure relevance, authority, or ranking potential. It measures repetition frequency, nothing else.
The Plain-Language Definition You Actually Need Before You Touch a Calculator
Here is the false assumption worth naming early: a higher keyword density does not signal stronger relevance to search engines.
It never did.
Keyword density is a count-based ratio. It tells you how many times a word appears per hundred words of text. A piece with 10 keyword mentions across 1,000 words has a 1% density rate [4]. That number says nothing about whether the article covers the topic well, whether readers stay on the page, or whether Google considers it authoritative.
The confusion happens because density sounds like it should matter. If you mention “project management software” more often, shouldn’t the page rank better for that phrase? No. That logic treats repetition as a signal of depth, and search engines stopped rewarding raw repetition a long time ago.
What the metric actually does: it counts. That is the whole job. This metric is a frequency ratio, calculated as the number of keyword occurrences divided by total words, multiplied by 100 [3]. Treating it as anything more than that creates decisions based on a number that was never designed to drive rankings.
Stop monitoring density as a performance indicator. Start using it as a proofreading pass.
The distinction matters operationally. A content team that targets a density percentage will pad copy, repeat phrases awkwardly, and sometimes reduce the precision of a sentence just to hit a ratio. A team that uses density as a ceiling check will write naturally, then verify the text does not sound mechanical before publishing.
One is a creation constraint. The other is a final review step.
How to Calculate keyword density in Under a Minute With Real Numbers
The formula has three steps. Count keyword occurrences. Count total words. Divide the first number by the second, then multiply by 100.
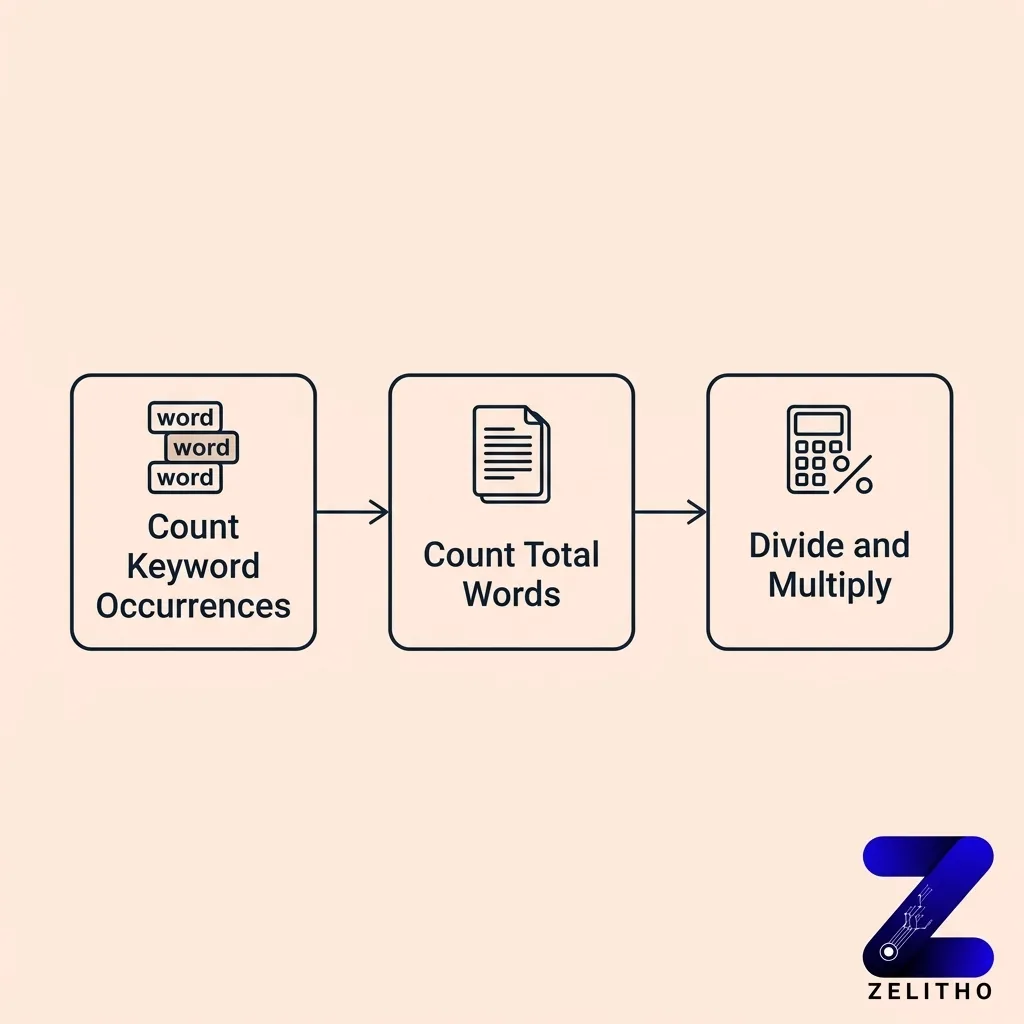
Written out: (keyword occurrences / total words) x 100 = keyword density percentage [3].
A concrete example makes this immediate. Take an article with 1,322 words and 23 keyword mentions [1][2]. Divide 23 by 1,322. The result is approximately 0.0174. Multiply by 100. The density is 1.74% [1].
A simpler version: 10 mentions in a 500-word article gives you 2% . That same calculation applied to a 1,000-word article with 10 mentions gives you 1% . Add 10 more mentions to that 1,000-word article, and you reach 2% .
Keyword Mentions | Total Words | Density Rate |
|---|---|---|
10 | 1,000 | 1% |
20 | 1,000 | 2% |
23 | 1,322 | 1.74% |
10 | 500 | 2% |
These are not targets. They are reference points for calibrating your audit.
You do not need a tool for this calculation. A word processor’s find-and-replace function shows keyword occurrences. Most document tools display total word count. The math takes under 60 seconds by hand.
The place where manual calculation beats automated tools: you read the sentences while you count. That reading step catches awkward phrasing that a density score alone would miss. A tool reports 1.8% and moves on. A manual count forces you to see each instance in context.
One practical note on multi-word phrases: count each full phrase as one occurrence, not as individual words. If your target term is “content marketing strategy,” one instance of that full phrase counts as one occurrence against total word count, not three.
What the Numbers Actually Tell You , and What They Cannot
A density range of 0.5% to 3% appears across multiple SEO references as a practical working band [2]. Crossing above 2% is a signal to check whether the text still reads naturally. Neither number is a ranking threshold.

That distinction is the entire point.
Search engines evaluate relevance through semantic signals, co-occurring terms, topic coverage, and user behavior data. A page with 1% density and strong topical depth outperforms a page with 2.5% density and thin coverage. The ratio is visible to a calculation. The depth is visible to readers and to machine learning models trained on how readers behave.
What density can legitimately flag: over-repetition that damages sentence flow. If a 200-word section of a 2,000-word article contains 20 keyword mentions, that section hits 10%. Reading that section aloud makes the problem obvious. The density calculation surfaced what careful editing should have caught.
What density cannot flag: missing subtopics, weak supporting evidence, low reading level, poor structure, or thin coverage of adjacent questions. Those problems produce underperforming content far more often than over-repetition does. Yet a density tool reports nothing about them.
A suggested target range of 1% to 3% [3] gives writers a loose reference, but treating it as a pass/fail score misuses the metric. Two pages with identical 1.5% density can differ dramatically in quality. One covers the topic with precision and varied vocabulary. The other repeats the same phrase mechanically while ignoring related concepts entirely. The metric cannot distinguish between them.
The Repetition Audit Framework positions density as one checkpoint in a larger editorial review, not as the review itself. Define the term clearly, calculate once, check sections that read awkwardly against the threshold, then move to topic coverage and structure. That sequence keeps the metric in its correct role.
Why Chasing a Density Target Hurts More Than It Helps
Consider what happens when a writer targets 2% density in a 1,000-word article. They need 20 keyword mentions. In practice, this produces sentences restructured around the phrase rather than around the idea. Clarity shrinks. The reader notices before any algorithm does.
The upper boundary worth keeping in mind: 200 keyword mentions in a 2,000-word article produces 10% density. No professional editor would approve that copy. It reads as spam because it is. But the same mechanical thinking that produces 10% also produces 2.5% when the writer targets a “safe” number. The behavior is identical. The degree of damage differs.
Google’s approach to keyword stuffing shifted significantly by 2011 [2]. Algorithmic updates began penalizing pages that repeated target phrases to manipulate rankings. The SEO tactic that once worked became a liability. Pages built around density targets lost visibility. Pages built around topic coverage held ground.
That history matters for a practical reason: any content system still optimizing for density percentage carries risk that predates the current decade.
The replacement habit is not complicated. Cover the topic. Use the natural vocabulary of the subject. Vary sentence structure. When the draft is complete, run the quick calculation. If density sits below 2% and the text reads cleanly, publish. If density exceeds 2% in a specific section, read that section aloud. Fix what sounds wrong. Do not add or remove mentions to adjust the percentage without reading first.
Stop targeting a percentage before writing. Start calculating once after writing.
That sequence removes the constraint from the creation phase and places the metric where it belongs: in the review phase.
One implementation caveat that most density guides omit: single-topic articles naturally produce higher density than multi-topic pieces. A 600-word explainer focused entirely on one term will accumulate mentions faster than a 2,000-word guide covering five related concepts. Adjust your review threshold by article type, not by a universal number applied to every page.
A reasonable operating standard: flag any section where the same phrase appears more than twice in a 100-word span. That local check is more useful than a document-level percentage, because readability problems appear at the paragraph level, not across an entire page.
Read More: What Is Keyword Mapping and Why It Matters for SEO
Keyword Density Has One Legitimate Job
Keyword density has one legitimate job: catching excess before it damages readability. It is not a ranking formula, not a content score, and not a substitute for covering a topic with depth and precision.
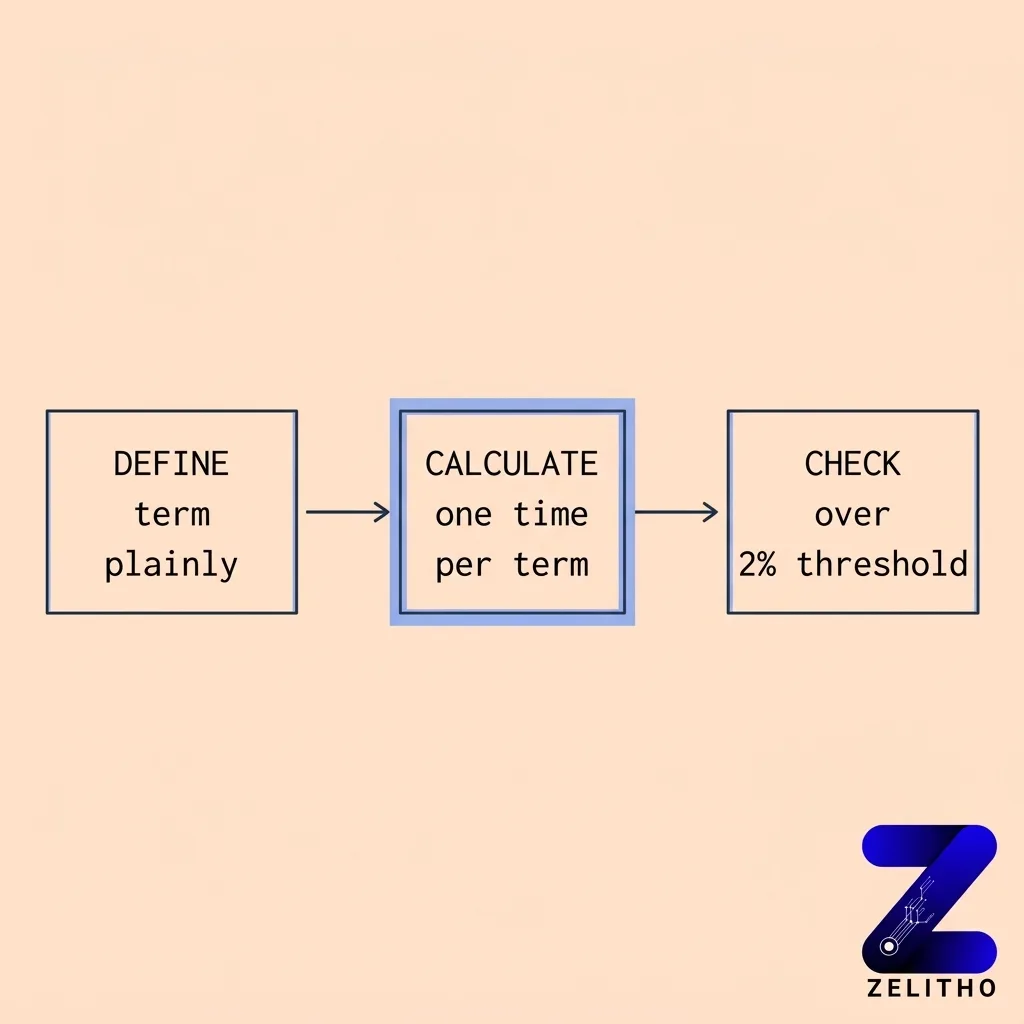
The Repetition Audit Framework gives you a repeatable process without turning measurement into obsession. Define the term plainly. Calculate once. Check whether any section exceeds the 2% threshold in a way that disrupts reading. That three-step process takes less than two minutes on any draft.
Use density as a ceiling detector, not a target setter. When the number stays low because the writing is clear and varied, the metric has done its job.
That is the only outcome worth optimizing for.
FAQ
Keyword density measures how often a target term appears in a piece of content relative to its total word count. The formula is: keyword occurrences divided by total words, multiplied by 100. It is a frequency ratio, not a relevance score. It tells you how often a word repeats, nothing more.
The 80/20 rule in SEO suggests that roughly 80% of your organic traffic comes from 20% of your pages or keywords. It directs attention toward identifying which content already performs and investing further in those assets. The practical application is prioritizing optimization and internal linking on high-performing pages rather than distributing effort evenly.
The 3 C’s of SEO are commonly identified as Content, Code, and Credibility. Content refers to the relevance and depth of what you publish. Code covers technical implementation including site structure and page speed. Credibility addresses backlink authority and trustworthiness signals.
The four keyword types are informational, navigational, commercial, and transactional. Informational keywords signal research intent. Navigational keywords target a specific site or brand. Commercial keywords reflect product or service comparison. Transactional keywords indicate purchase or conversion intent. Matching content type to keyword intent produces stronger page-level relevance.
The four pillars of SEO are technical SEO, on-page optimization, off-page authority, and content. Technical SEO covers crawlability and site health. On-page optimization addresses structure, headings, and keyword placement. Off-page authority focuses on backlinks and brand signals. Content brings all three together through relevance and depth.
References and Citations
[1]https://www.hikeseo.co/learn/onsite/keyword-density-in-seo
[2]https://www.semrush.com/blog/keyword-density/
[3]https://www.geeksforgeeks.org/techtips/what-is-keyword-density/